

Nenhuma notícia mais específica foi divulgada sobre o que é Q*, mas algumas pessoas especulam a partir do nome que ele pode estar relacionado ao Q-Learning.
Criado em 1989, o Q-Learning é um algoritmo de aprendizagem por reforço que não requer modelagem do ambiente, nem mesmo funções de transferência ou funções de recompensa com fatores aleatórios, podendo ser adaptado sem modificações especiais. Comparado com outros algoritmos de aprendizagem por reforço, o Q-Learning concentra-se em aprender o valor de cada par estado/ação para decidir qual ação trará a maior recompensa no longo prazo, em vez de aprender diretamente a estratégia de ação em si.
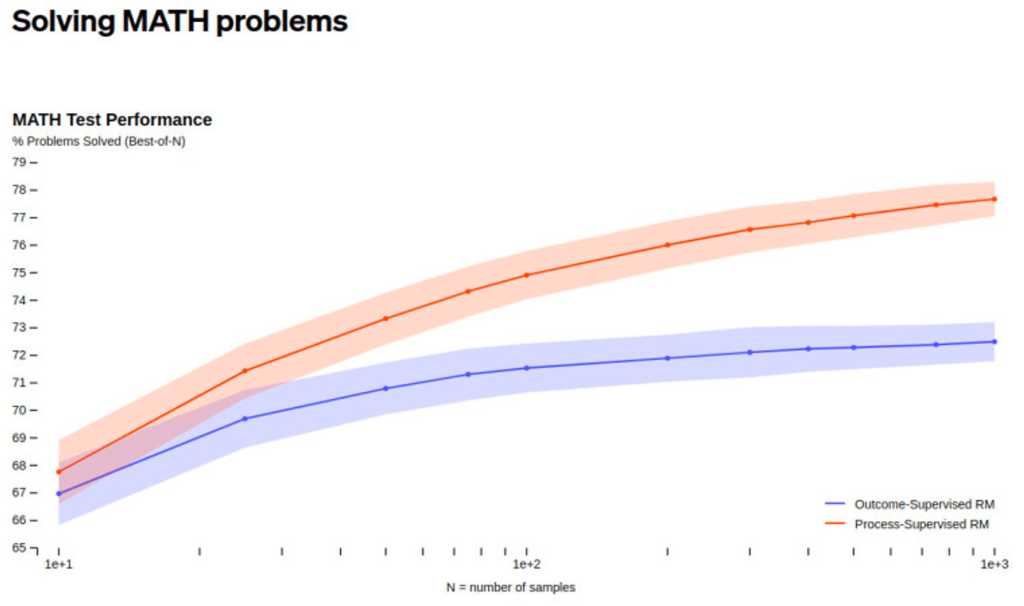
A segunda especulação está relacionada com o anúncio da OpenAI em maio sobre resoluções de problemas matemáticos através de “supervisão de processos” em vez de “supervisão de resultados”. Porem, os nomes de Jakub Pachocki e Szymon Sidor não aparecem na lista de contribuições desta pesquisa.
Também há especulações de que Noam Brown, o “pai do poker AI” que se juntou à OpenAI em julho, também possa estar relacionado com este projeto. Quando ingressou, disse que queria generalizar métodos que só eram aplicáveis a jogos do passado. O raciocínio pode ser 1.000 vezes mais lento e caro, mas pode descobrir novas drogas ou comprovar conjecturas matemáticas.
Embora ainda haja muita especulação, se os dados sintéticos e a aprendizagem por reforço podem levar a IA ao próximo estágio, esse tópicos tornou-se um dos mais discutidos na ultimas semanas.
O cientista da NVIDIA Fan Linxi acredita que os dados sintéticos fornecerão trilhões de tokens de treinamento de alta qualidade. A questão principal é como manter a qualidade e evitar gargalos prematuros. em seguida Elon Musk concordou, observando que todos os livros já escritos por humanos caberiam em um único disco rígido e que os dados sintéticos iriam muito além disso. No entanto, LeCun, um dos três vencedores do Prémio Turing, acredita que mais dados sintéticos são apenas uma medida provisória e, em última análise, a IA precisa de ser capaz de aprender com muito poucos dados, como humanos ou animais.
Cameron R. Wolfe, Ph.D. na Rice University, disse que o Q-Learning pode não ser o segredo para desbloquear a AGI.
Mas combinar “dados sintéticos” com “algoritmos de aprendizagem por reforço eficientes em termos de dados” pode ser a chave para o avanço do atual paradigma de pesquisa em inteligência artificial.
Ele também disse que o ajuste fino por meio do aprendizado por reforço é o segredo para treinar grandes modelos de alto desempenho, como Chat GPT / GPT-4. No entanto, a aprendizagem por reforço é inerentemente ineficiente em termos de dados, e o ajuste fino da aprendizagem por reforço usando conjuntos de dados rotulados manualmente é muito caro. Com isto em mente, o avanço da investigação em IA (pelo menos no paradigma atual) dependerá fortemente de dois objetivos fundamentais:
- Fazer com que o aprendizado por reforço tenha um melhor desempenho com menos dados.
- Usar modelos grandes e uma pequena quantidade de dados anotados manualmente para sintetizar dados de alta qualidade sempre que possível
… se seguirmos o paradigma de previsão do próximo token do Transformer somente para decodificador (ou seja, pré-treinamento -> SFT -> RLHF) … as duas abordagens combinadas tornarão técnicas de treinamento de ponta disponíveis para todos, não apenas apenas equipes de pesquisa com muito financiamento!
Mais uma coisa
Ninguém dentro da OpenAI ainda respondeu às notícias de Q*. Mas Altman acaba de revelar que teve várias horas de conversas amigáveis com o fundador do Quora, Adam D’Angelo, que permanece no conselho.
Parece que, independentemente de Adam D’Angelo estar ou não por trás do incidente, como todos especularam, um acordo foi alcançado.


Seja o primeiro a comentar